Hi there  Welcome to my Homepage!
Welcome to my Homepage!
About Me
I am a fourth-year undergraduate student at Shantou University. I will join the JPG Lab at Central South University, where I will pursue my master’s degree under the supervision of Prof. Alex Jinpeng Wang, focusing on World Model and Robotic Learning. During my undergraduate studies, I was fortunate to collaborate closely with Prof. Cheng Liu on research in Multimodal Learning and AI4S.
🎯 I am currently developing world models and investigating their fundamental importance. Additionally, I am exploring their applications in robotic learning and autonomous driving.
🤝 I am eager to discuss potential collaborations and am actively seeking industry internship opportunities in World Model. Please feel free to contact me via email if you are interested.
News
- [SMART] is accepted in IEEE TCSVT 🔥
- [scRCL] is accepted in AAAI 2026 🔥
- [NeuCGC] is accepted in IEEE TKDE 🔥
- [CVNC] is accepted in ICME 2025 🔥
Selected Publication
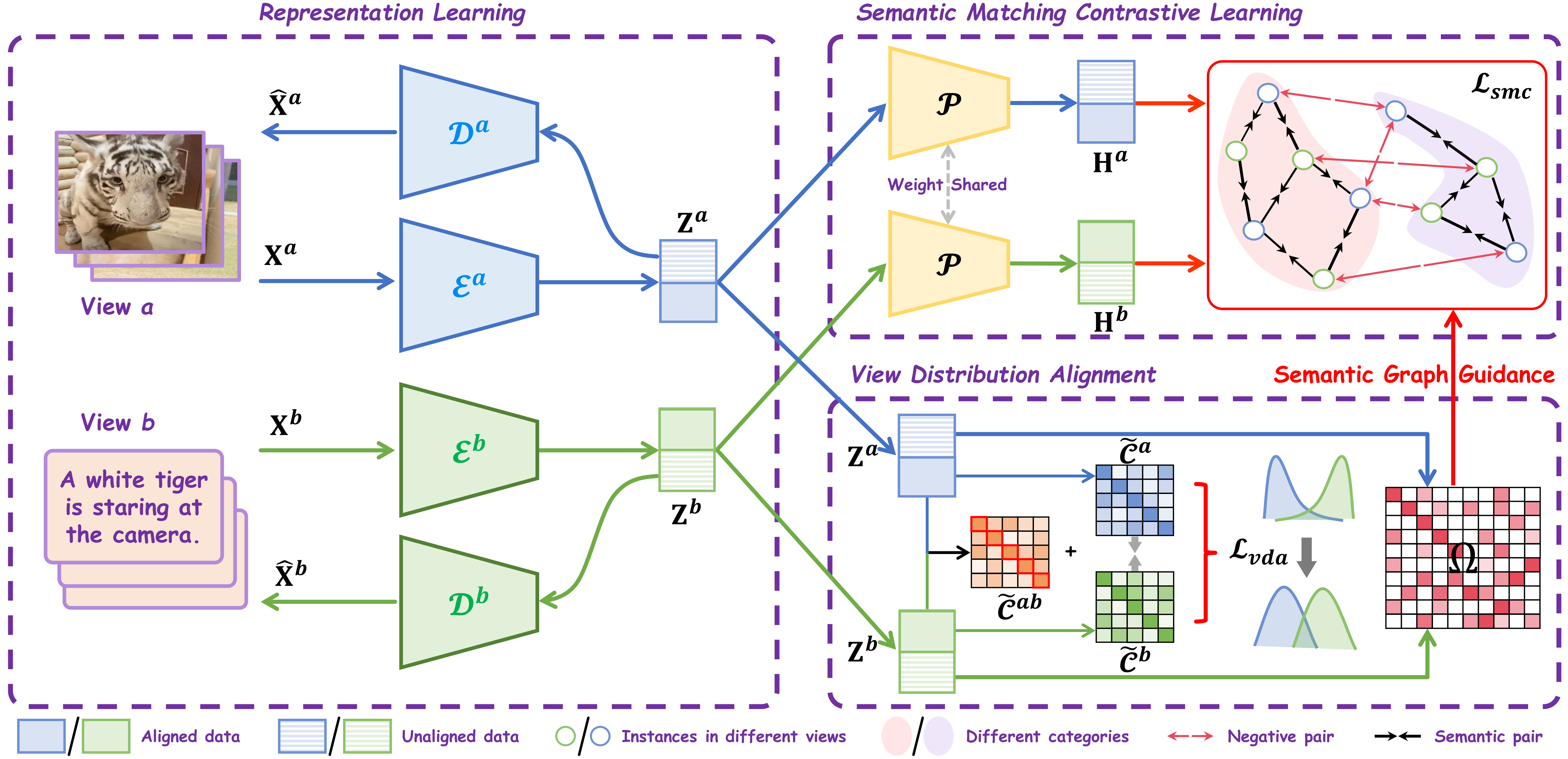
SMART: Semantic Matching Contrastive Learning for Partially View-Aligned Clustering IEEE Transactions on Circuits and Systems for Video Technology (IEEE TCSVT)
Multi-view clustering has been empirically shown to improve learning performance by leveraging the inherent complementary information across multiple views of data. However, in real-world scenarios, collecting strictly aligned views is challenging, and learning from both aligned and unaligned data becomes a more practical solution. Partially View-aligned Clustering (PVC) aims to learn correspondences between misaligned view samples to better exploit the potential consistency and complementarity across views, including both aligned and unaligned data. However, most existing PVC methods fail to leverage unaligned data to capture the shared semantics among samples from the same cluster. Moreover, the inherent heterogeneity of multi-view data induces distributional shifts in representations, leading to inaccuracies in establishing meaningful correspondences between cross-view latent features and, consequently, impairing learning effectiveness. To address these challenges, we propose a Semantic MAtching contRasTive learning model (SMART) for PVC. The main idea of our approach is to alleviate the influence of cross-view distributional shifts, thereby facilitating semantic matching contrastive learning to fully exploit semantic relationships in both aligned and unaligned data. Specifically, we mitigate view distribution shifts by aligning cross-view covariance matrices, which enables the inference of a semantic graph for all data. Guided by the learned semantic graph, we further exploit semantic consistency across views through semantic matching contrastive learning. After the optimization of the above mechanisms, our model smoothly performs semantic matching for different view embeddings instead of the cumbersome view realignment, which enables the learned representations to enjoy richer category-level semantics and stronger robustness. Extensive experiments on eight benchmark datasets demonstrate that our method consistently outperforms existing approaches on the PVC problem.
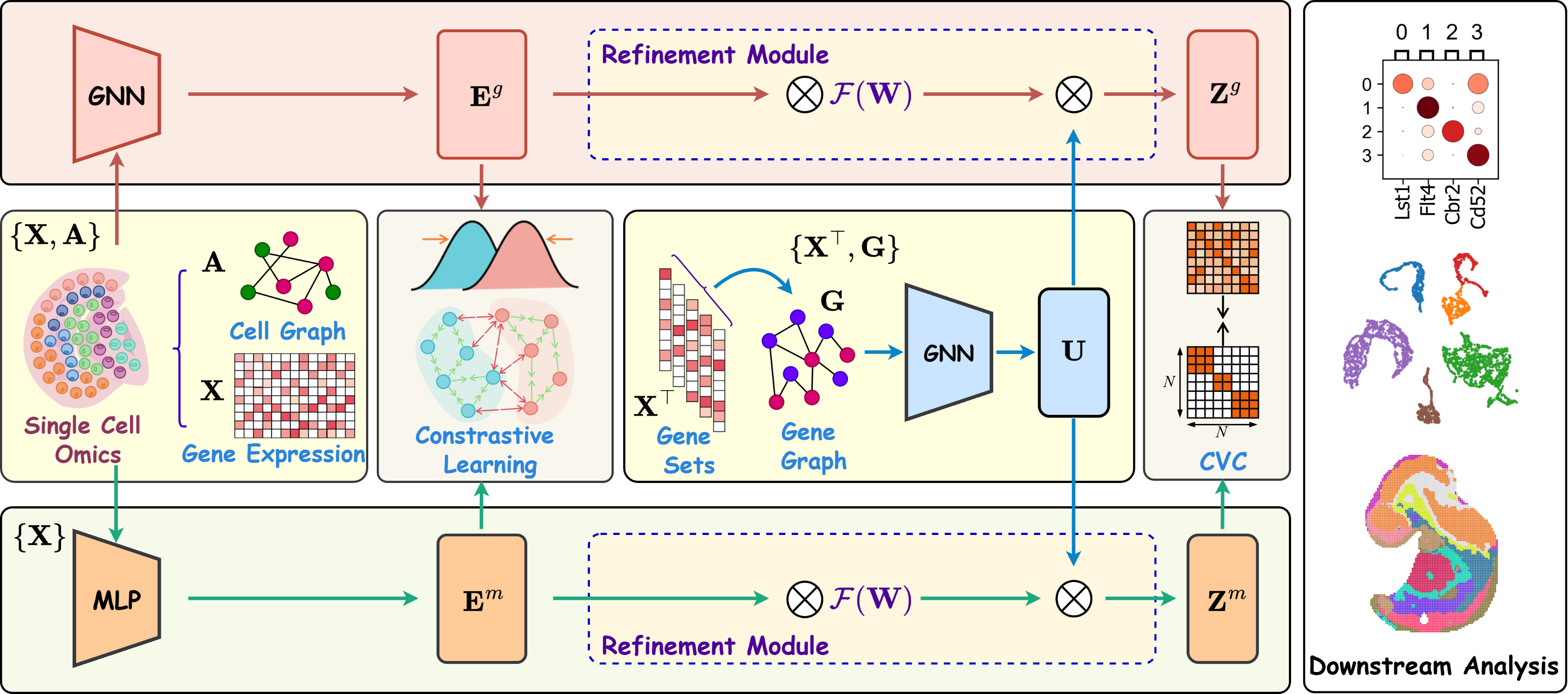
Refinement Contrastive Learning of Cell-Gene Associations for Unsupervised Cell Type Identification The 40th Annual AAAI Conference on Artificial Intelligence (AAAI 2026)
Unsupervised cell type identification is crucial for uncovering and characterizing heterogeneous populations in single cell omics studies. Although a range of clustering methods have been developed, most focus exclusively on intrinsic cellular structure and ignore the pivotal role of cell-gene associations, which limits their ability to distinguish closely related cell types. To this end, we propose a Refinement Contrastive Learning framework (scRCL) that explicitly incorporates cell-gene interactions to derive more informative representations. Specifically, we introduce two contrastive distribution alignment components that reveal reliable intrinsic cellular structures by effectively exploiting cell-cell structural relationships. Additionally, we develop a refinement module that integrates gene-correlation structure learning to enhance cell embeddings by capturing underlying cell-gene associations. This module strengthens connections between cells and their associated genes, refining the representation learning to exploiting biologically meaningful relationships. Extensive experiments on several single‑cell RNA‑seq and spatial transcriptomics benchmark datasets demonstrate that our method consistently outperforms state-of-the-art baselines in cell-type identification accuracy. Moreover, downstream biological analyses confirm that the recovered cell populations exhibit coherent gene‑expression signatures, further validating the biological relevance of our approach.
@ARTICLE{11268507, author={Peng, Liang and Ye, Yixuan and Liu, Cheng and Che, Hangjun and Wang, Fei and Yu, Zhiwen and Wu, Si and Wong, Hau-San}, journal={IEEE Transactions on Circuits and Systems for Video Technology}, title={SMART: Semantic Matching Contrastive Learning for Partially View-Aligned Clustering}, year={2025}, volume={}, number={}, pages={1-1}, keywords={Muti-View Clustering;Partially View-Aligned Clustering;Contrastive Learning}, doi={10.1109/TCSVT.2025.3636507}}
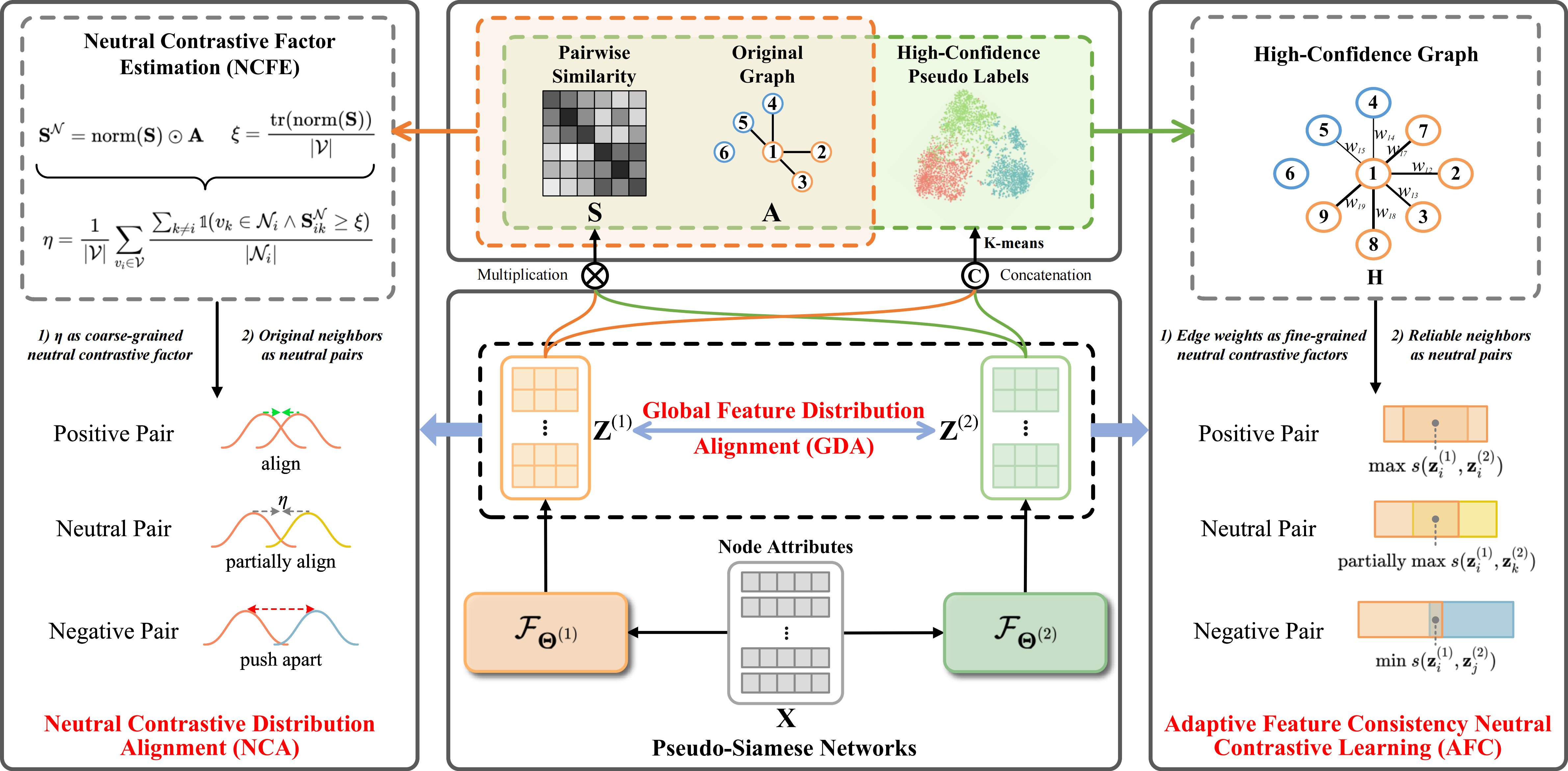
Trustworthy Neighborhoods Mining: Homophily-Aware Neutral Contrastive Learning for Graph Clustering IEEE Transactions on Knowledge and Data Engineering (IEEE TKDE)
Recently, neighbor-based contrastive learning has been introduced to effectively exploit neighborhood information for clustering. However, these methods rely on the homophily assumption—that connected nodes share similar class labels and should therefore be close in feature space—which fails to account for the varying homophily levels in real-world graphs. As a result, applying contrastive learning to low-homophily graphs may lead to indistinguishable node representations due to unreliable neighborhood information, making it challenging to identify trustworthy neighborhoods with varying homophily levels in graph clustering. To tackle this, we introduce a novel neighborhood Neutral Contrastive Graph Clustering method NeuCGC that extends traditional contrastive learning by incorporating neutral pairs—node pairs treated as weighted positive pairs, rather than strictly positive or negative. These neutral pairs are dynamically adjusted based on the graph’s homophily level, enabling a more flexible and robust learning process. Leveraging neutral pairs in contrastive learning, our method incorporates two key components: 1) an adaptive contrastive neighborhood distribution alignment that adjusts based on the homophily level of the given attribute graph, ensuring effective alignment of neighborhood distributions, and 2) a contrastive neighborhood node feature consistency learning mechanism that leverages reliable neighborhood information from high-confidence graphs to learn robust node representations, mitigating the adverse effects of varying homophily levels and effectively exploiting highly trustworthy neighborhood information. Experimental results demonstrate the effectiveness and robustness of our approach, outperforming other state-of-the-art graph clustering methods.
@ARTICLE{11206540,
author={Peng, Liang and Ye, Yixuan and Liu, Cheng and Che, Hangjun and Leung, Man-Fai and Wu, Si and Wong, Hau-San},
journal={IEEE Transactions on Knowledge and Data Engineering},
title={Trustworthy Neighborhoods Mining: Homophily-Aware Neutral Contrastive Learning for Graph Clustering},
year={2025},
pages={1-15},
keywords={Contrastive learning;Reliability;Computer science;Representation learning;Estimation;Silicon;Semantics;Robustness;Nickel;Learning systems;Contrastive Graph Clustering;Graph Homophily},
doi={10.1109/TKDE.2025.3622998}} 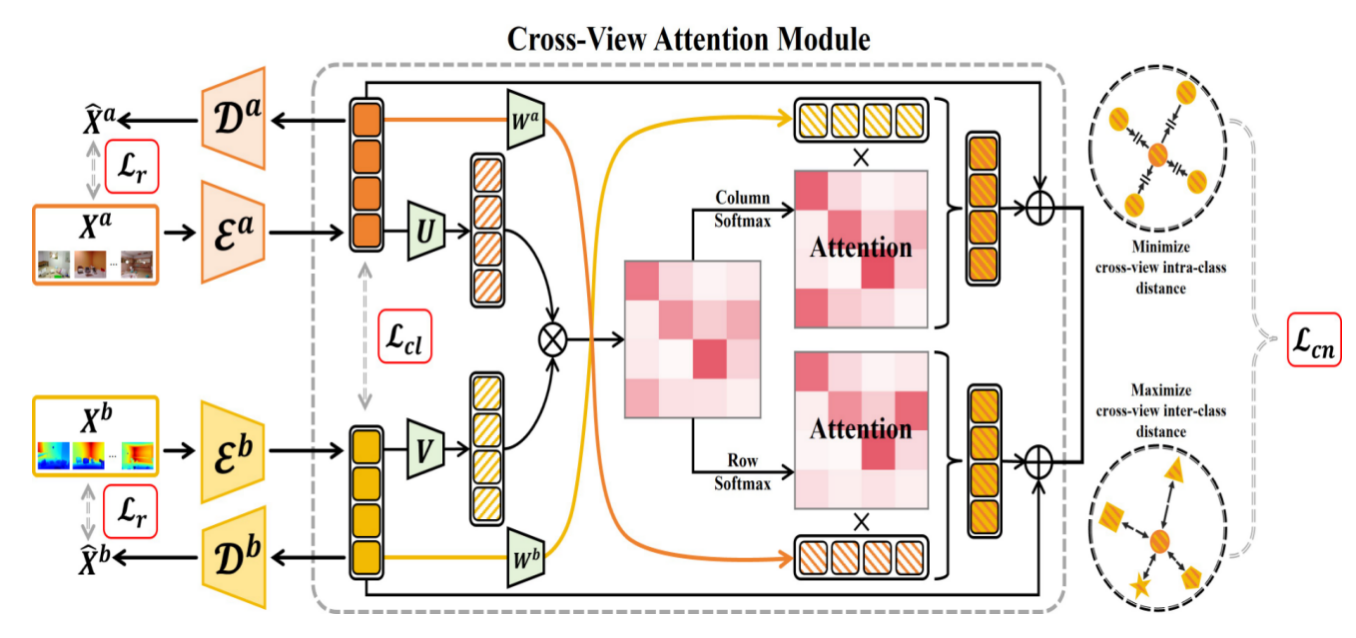
Cross-View Neighborhood Contrastive Multi-View Clustering with View Mixup Feature Learning The 26th IEEE International Conference on Multimedia and Expo (ICME 2025)
Multi-view clustering (MVC) has shown that leveraging both consistency and complementary information across views enhances clustering performance. However, most existing methods focus on aligning features into the same dimension, often neglecting cross-view heterogeneity and introducing discrepancies. To address this, we propose a novel multi-view clustering framework that combines cross-view neighborhood contrastive learning with a cross-attention view-mixup feature learning mechanism. Specifically, the cross-attention view-mixup module learns view-invariant feature representations by capturing complementary and consistent information, while the neighborhood contrastive learning module uncovers semantic structures across views based on the learned mixup features. By implicitly performing feature mixup across views and effectively integrating cross-view neighborhood contrastive learning, our method alleviates cross-view discrepancies and enables more effective integration of complementary and consistent information, ultimately enhancing clustering performance. Experiments conducted on several real datasets demonstrate the effectiveness of our proposed method in comparision with several representative MVC approaches.
@INPROCEEDINGS{11209498,
author={Ye, Yixuan and Zhang, Yang and Peng, Liang and Li, Rui and Liu, Cheng and Wu, Si and Wong, Hau-San},
booktitle={2025 IEEE International Conference on Multimedia and Expo (ICME)},
title={Cross-View Neighborhood Contrastive Multi-View Clustering with View Mixup Feature Learning},
year={2025},
pages={1-6},
keywords={Representation learning;Semantics;Contrastive learning;Benchmark testing;Multi-view clustering;Cross-view contrastive learning;Cross-attention},
doi={10.1109/ICME59968.2025.11209498}} Awards
- National Scholarship 2025
Service
- Reviewer for ICME 2025-2026
- Reviewer for IEEE TKDE
Experience

Central South University July 2026 - June 2029
M.S at
JPG 
Shantou University
Sep 2022 - July 2026
B.E rank 1/79
I truly believe that great ideas and improvements come from open discussions and debates in academia. If you have any thoughts, disagreements with my work, or fresh ideas you’d like to share, I’d be really grateful to hear from you. I am incredibly fortunate to have met many friends who have helped me along the way, and in turn, I am always willing to chat and offer any assistance I can to others.
If you’ve got any questions about my research or if you’ve tried reaching out through GitHub issues and haven’t heard back, please don’t hesitate to drop me an email.
Please note that I am only interested in discussing intriguing problems and insights, not metrics. If you are inclined to discuss publication or citation numbers, rely on numerical indicators to quantify individuals, or compare me to others, please refrain from contacting me.
My preferred email: yixuanye12@gmail.com
